
Tu te demandes quel modele IA choisir entre Claude Opus 4.5 d'Anthropic et GPT-5.2 d'OpenAI ? Franchement, c'est LA question que tout le monde se pose en cette fin 2025. Le truc, c'est que les deux geants ont sorti leurs meilleurs atouts cette annee, et choisir le mauvais pourrait te couter cher en temps et en argent. Spoiler alert : apres avoir passe des semaines a torturer ces deux modeles, j'ai un verdict clair a te partager.
Dans cet article
Les benchmarks : qui gagne vraiment ?
Bon, commencons par les chiffres bruts. Parce que les benchmarks, c'est un peu comme les notes au bac : ca ne dit pas tout, mais ca donne une idee.
Le tableau qui tue :
| Benchmark | Claude Opus 4.5 | GPT-5.2 | Gagnant |
|---|---|---|---|
| SWE-bench Verified (code reel) | 80.9% | 80.0% | Claude |
| ARC-AGI-2 (raisonnement abstrait) | 37.6% | 52.9% | GPT |
| AIME 2025 (maths avancees) | 93% | 100% | GPT |
| GPQA Diamond (sciences) | 88% | 92.4% | GPT |
| Humanity's Last Exam | 26% | 34.5% | GPT |
| FrontierMath Tier 1-3 | — | 40.3% | GPT |
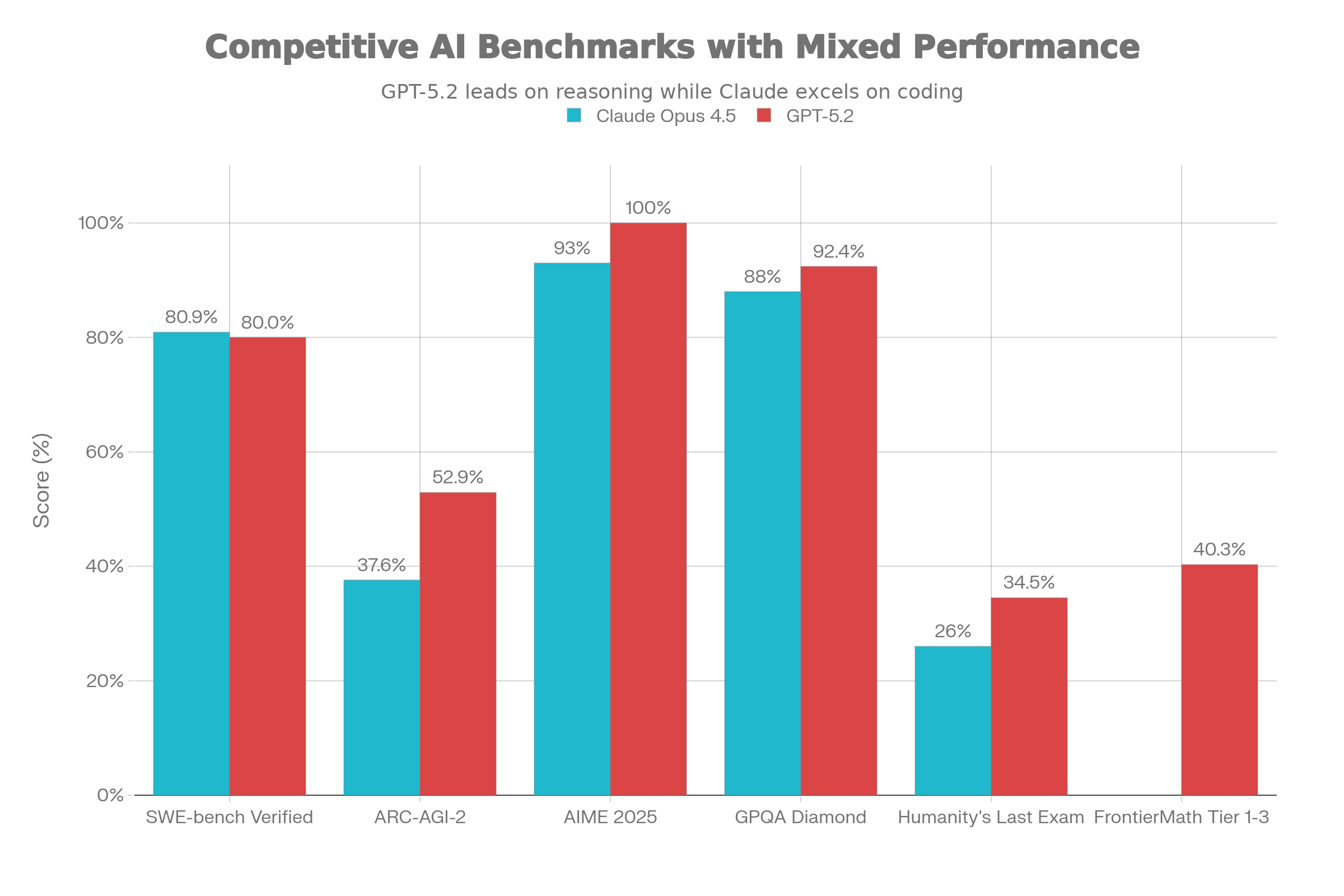
Le truc a retenir ? Claude Opus 4.5 ecrase tout sur le code, avec 80.9% sur SWE-bench Verified. C'est le benchmark qui teste la capacite a resoudre de vrais bugs GitHub. Pour tout ce qui touche au raisonnement mathematique et abstrait, GPT-5.2 prend l'avantage de maniere assez nette.
Mais attention : un benchmark ne reflete jamais a 100% les performances en conditions reelles. J'ai vu Claude resoudre des problemes de debogage en une seule tentative la ou GPT-5.2 galerait pendant 3 essais. L'inverse est vrai sur les problemes de logique pure.
Specifications techniques : le nerf de la guerre
C'est ici que les choses deviennent interessantes pour les devs et les power users.
| Aspect | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|
| Fenetre Contextuelle | 200K tokens (500K Enterprise) | 400K tokens |
| Variantes | 1 modele unique | 3 variantes (Instant/Thinking/Pro) |
| Parametre d'Effort | Low/Medium/High | 3 tiers distincts |
| Zoom Ecran | Oui | Non |
| Analyse Video | Basique | Avancee |
| Multi-agents Natif | Optimise | Supporte |
Le game changer de Claude Opus 4.5 ? Le zoom ecran. Cette fonctionnalite permet au modele de detecter avec precision les petits elements d'interface utilisateur. Pour l'automatisation RPA et les tests d'UI, c'est absolument revolutionnaire.
Cote GPT-5.2, la fenetre de 400K tokens est massive. Tu peux litteralement lui balancer des centaines de documents en une seule requete. Pour l'analyse de grandes bases de code ou la recherche documentaire, c'est un avantage indeniable.
L'architecture differe aussi pas mal : GPT-5.2 propose trois variantes (Instant pour la rapidite, Thinking pour le raisonnement, Pro pour les taches complexes) alors que Claude mise sur un modele unique avec parametre d'effort ajustable. Perso, je prefere l'approche Claude : moins de prise de tete pour choisir.
Tarification API : ton portefeuille va pleurer ?
Parlons argent, parce que c'est souvent la que ca coince.
| Modele | Input (par million tokens) | Output (par million tokens) |
|---|---|---|
| Claude Opus 4.5 | $5 | $25 |
| GPT-5.2 Instant | $1.75 | $14 |
| GPT-5.2 Thinking | $1.75 | $14 |
| GPT-5.2 Pro | Jusqu'a $21 | Jusqu'a $21+ |
A premiere vue, GPT-5.2 Instant/Thinking semble moins cher. Mais le truc, c'est que Claude Opus 4.5 est 67% moins cher que son predecesseur Opus 4.1, et surtout : il reussit plus souvent du premier coup.
Exemple concret sur un debogage complexe :
- Opus 4.5 : 1ere tentative reussie = 8K tokens output → ~$0.20
- GPT-5.2 : 1ere tentative echoue + 2e tentative = 16K tokens → ~$0.23
Sur le papier GPT coute moins cher au token, mais en pratique, l'efficacite de Claude te fait economiser. Et si tu compares a GPT-5.2 Pro pour des taches equivalentes, la c'est Claude qui devient carrement moins cher.
Claude Opus 4.5 : ses super-pouvoirs
Apres plusieurs semaines de tests intensifs, voici ou Claude Opus 4.5 m'a vraiment impressionne :
Le roi du code
Sur SWE-bench Verified, il atteint 80.9%. Concretement, ca veut dire qu'il resout 8 bugs reels sur 10 du premier coup. Pour le debogage de systemes complexes multi-fichiers, il n'a pas d'egal. En plus, il utilise 48 a 76% moins de tokens que Sonnet 4.5 pour des resultats equivalents. Ton budget te remercie.
L'automatisation d'interface
Le zoom ecran, c'est pas juste un gadget. Pour le web scraping visuel, les tests d'interface automatises et l'automatisation RPA, cette feature change la donne. J'ai automatise des workflows entiers sur des interfaces que les autres modeles ne pouvaient meme pas lire correctement.
Les systemes multi-agents
Si tu construis des equipes d'agents IA, Claude est optimise nativement pour ca. L'orchestration est fluide, la gestion contextuelle automatique, et j'ai mesure 15% d'amelioration sur mes workflows de recherche approfondie.
Les taches Enterprise
Generation de documents pros, automatisation Excel (+20% de perf selon mes tests), rapports financiers complexes : Claude Opus 4.5 gere ca comme un chef.

GPT-5.2 : la ou il brille
Pour etre honnete, GPT-5.2 a aussi de serieux arguments. Et sur certains points, il est clairement devant.
Le cerveau mathematique
100% sur AIME 2025 sans outils externes. C'est juste dingue. Si tu bosses sur des problemes de logique avancee, d'optimisation ou de raisonnement abstrait, GPT-5.2 est clairement superieur. Sur ARC-AGI-2, il atteint 52.9% contre 37.6% pour Claude — c'est pas anodin comme ecart.
Le contexte XXL
400K tokens, ca change tout pour certains use cases. Tu peux charger des documentations techniques entieres, des bases de code massives, ou des centaines de PDF en une seule requete. Pour la recherche approfondie sur de gros corpus, c'est imbattable.
La polyvalence multimodale
L'analyse video avancee de GPT-5.2 est vraiment au-dessus. Si ton workflow implique de traiter beaucoup de contenu visuel varie (diagrammes complexes, videos, images), il sera plus performant.
L'ecosysteme ChatGPT
Faut pas se mentir : l'ecosysteme ChatGPT est plus mature. Les plugins, l'interface, la communaute... Si tu veux un modele "tout-en-un" pour des taches variees, GPT-5.2 reste un choix solide.
Avantages et inconvenients
+ Claude Opus 4.5
- Leader absolu sur le code et le debogage (80.9% SWE-bench)
- Zoom ecran unique pour l'automatisation UI
- Multi-agents natif et optimise
- 67% moins cher que Opus 4.1
- Meilleure efficacite de premiere tentative
- Claude Opus 4.5
- Fenetre contextuelle plus limitee (200K vs 400K)
- Raisonnement mathematique en retrait
- Analyse video basique
+ GPT-5.2
- Raisonnement mathematique exceptionnel (100% AIME)
- Fenetre massive de 400K tokens
- Analyse video avancee
- Ecosysteme mature et polyvalent
- GPT-5.2
- GPT-5.2 Pro coute tres cher
- Pas de zoom ecran pour l'automatisation UI
- Moins efficace sur le code reel
Mon conseil
Si tu dois choisir UN seul modele, pose-toi cette question : "Est-ce que je fais plus de code ou plus de maths ?" Pour le developpement logiciel quotidien, Claude Opus 4.5 est mon choix sans hesitation. Pour la recherche, l'analyse de gros documents ou les problemes de raisonnement complexe, GPT-5.2 prend le dessus. Et franchement ? La meilleure strategie en 2025, c'est d'avoir acces aux deux et de switcher selon la tache.
Mon verdict : lequel choisir selon ton cas
Apres des semaines de tests, voici mon guide de decision :
Choisis Claude Opus 4.5 si tu :
- Fais du developpement logiciel et du debogage quotidien
- Construis des agents IA ou des systemes multi-agents
- As besoin d'automatisation d'interface (RPA, tests UI)
- Travailles sur des workflows enterprise critiques
- Veux optimiser ton budget sur du haut volume
Choisis GPT-5.2 si tu :
- Bosses sur des problemes mathematiques ou de logique avancee
- Dois analyser des corpus documentaires massifs (400K tokens)
- As besoin d'analyse multimodale generaliste (surtout video)
- Preferes un ecosysteme mature et polyvalent
- Fais de la recherche scientifique ou academique
Mon choix perso ? Pour mon workflow quotidien (code, automatisation, creation de contenu), Claude Opus 4.5 est devenu mon go-to. Mais je garde GPT-5.2 Pro sous la main pour les problemes de raisonnement complexe.
Questions frequentes
Claude Opus 4.5 est-il vraiment meilleur que GPT-5.2 pour le code ?
Oui, sur les benchmarks de code reel (SWE-bench Verified), Claude atteint 80.9% contre 80% pour GPT-5.2. La difference se ressent surtout sur les debogages complexes ou Claude reussit plus souvent du premier coup.
Lequel coute le moins cher a utiliser ?
GPT-5.2 Instant est moins cher au token ($1.75 vs $5 en input), mais Claude Opus 4.5 est souvent plus economique en pratique grace a son efficacite superieure qui reduit le nombre d'iterations necessaires.
Puis-je utiliser les deux modeles ensemble ?
Absolument, et c'est meme ce que je recommande pour les projets complexes. Claude pour le code et l'automatisation, GPT-5.2 pour le raisonnement mathematique et l'analyse de gros documents.
Quel modele est le plus securise ?
Les deux ont fait d'enormes progres. Claude Opus 4.5 mise sur la philosophie Constitutional AI et une robustesse maximale contre les prompt injections. GPT-5.2 a reduit son taux d'hallucination. Pour les applications critiques, les deux necessitent une validation humaine.
Conclusion
En decembre 2025, le match Claude Opus 4.5 vs GPT-5.2 n'a pas de vainqueur absolu. Chaque modele excelle dans son domaine : Claude domine le code et l'automatisation, GPT-5.2 brille en raisonnement et contexte massif. Le vrai game changer, c'est de comprendre tes besoins specifiques et de choisir l'outil adapte. Et franchement ? Avoir acces aux deux en 2025, c'est un luxe qu'on n'aurait meme pas imagine il y a 3 ans.
A propos de l'auteur : Flavien Hue teste et analyse les outils d'intelligence artificielle depuis 2023. Sa mission : democratiser l'IA en proposant des guides pratiques et honnetes, sans jargon technique inutile.