
Wondering which AI model to choose between Claude Opus 4.5 from Anthropic and GPT-5.2 from OpenAI? Honestly, that's THE question everyone's asking at the end of 2025. The thing is, both giants have released their best offerings this year, and picking the wrong one could cost you time and money. Spoiler alert: after spending weeks pushing both models to their limits, I have a clear verdict to share with you.
In this article
The benchmarks: who really wins?
Alright, let's start with the raw numbers. Because benchmarks are a bit like exam grades: they don't tell the whole story, but they give you an idea.
The killer table:
| Benchmark | Claude Opus 4.5 | GPT-5.2 | Winner |
|---|---|---|---|
| SWE-bench Verified (real code) | 80.9% | 80.0% | Claude |
| ARC-AGI-2 (abstract reasoning) | 37.6% | 52.9% | GPT |
| AIME 2025 (advanced math) | 93% | 100% | GPT |
| GPQA Diamond (science) | 88% | 92.4% | GPT |
| Humanity's Last Exam | 26% | 34.5% | GPT |
| FrontierMath Tier 1-3 | - | 40.3% | GPT |
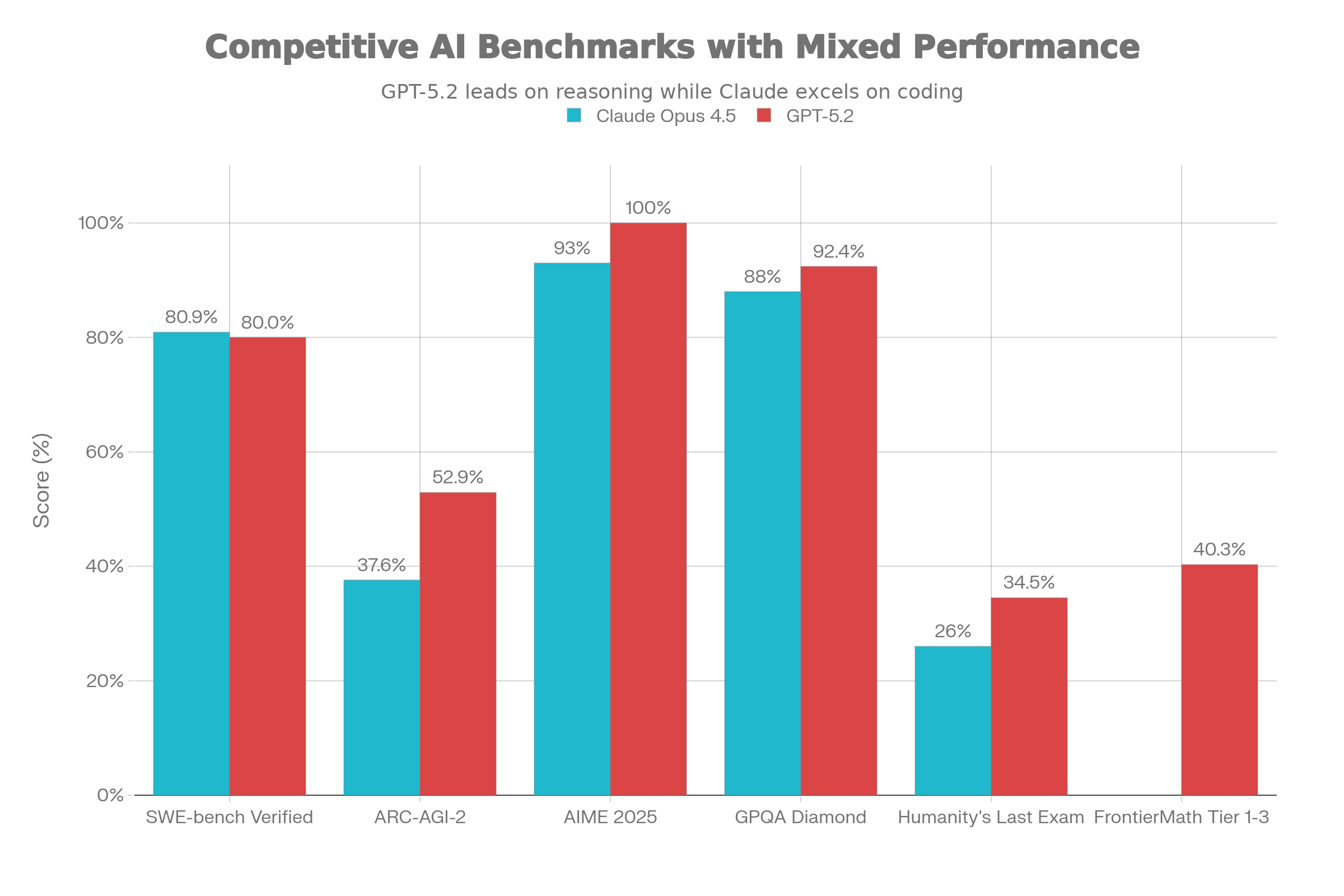
The key takeaway? Claude Opus 4.5 crushes it on code, with 80.9% on SWE-bench Verified. That's the benchmark testing the ability to solve real GitHub bugs. For everything related to mathematical and abstract reasoning, GPT-5.2 takes a clear lead.
But beware: a benchmark never reflects 100% of real-world performance. I've seen Claude solve debugging problems on the first try where GPT-5.2 struggled through 3 attempts. The reverse is true for pure logic problems.
Technical specifications: the heart of the matter
This is where things get interesting for devs and power users.
| Aspect | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|
| Context Window | 200K tokens (500K Enterprise) | 400K tokens |
| Variants | 1 single model | 3 variants (Instant/Thinking/Pro) |
| Effort Parameter | Low/Medium/High | 3 distinct tiers |
| Screen Zoom | Yes | No |
| Video Analysis | Basic | Advanced |
| Native Multi-Agent | Optimized | Supported |
The game changer for Claude Opus 4.5? Screen zoom. This feature allows the model to precisely detect small user interface elements. For RPA automation and UI testing, it's absolutely revolutionary.
On GPT-5.2's side, the 400K token window is massive. You can literally throw hundreds of documents at it in a single request. For analyzing large codebases or document research, it's an undeniable advantage.
The architecture also differs quite a bit: GPT-5.2 offers three variants (Instant for speed, Thinking for reasoning, Pro for complex tasks) while Claude relies on a single model with adjustable effort parameter. Personally, I prefer Claude's approach: less headache when choosing.
API pricing: will your wallet suffer?
Let's talk money, because that's often where things get tricky.
| Model | Input (per million tokens) | Output (per million tokens) |
|---|---|---|
| Claude Opus 4.5 | $5 | $25 |
| GPT-5.2 Instant | $1.75 | $14 |
| GPT-5.2 Thinking | $1.75 | $14 |
| GPT-5.2 Pro | Up to $21 | Up to $21+ |
At first glance, GPT-5.2 Instant/Thinking seems cheaper. But here's the thing: Claude Opus 4.5 is 67% cheaper than its predecessor Opus 4.1, and more importantly: it succeeds more often on the first try.
Real-world example on complex debugging:
- Opus 4.5: 1st attempt succeeds = 8K tokens output -> ~$0.20
- GPT-5.2: 1st attempt fails + 2nd attempt = 16K tokens -> ~$0.23
On paper GPT costs less per token, but in practice, Claude's efficiency saves you money. And if you compare it to GPT-5.2 Pro for equivalent tasks, Claude becomes clearly cheaper.
Claude Opus 4.5: its superpowers
After several weeks of intensive testing, here's where Claude Opus 4.5 really impressed me:
The king of code
On SWE-bench Verified, it achieves 80.9%. Concretely, this means it solves 8 out of 10 real bugs on the first try. For debugging complex multi-file systems, it has no equal. Plus, it uses 48 to 76% fewer tokens than Sonnet 4.5 for equivalent results. Your budget thanks you.
Interface automation
Screen zoom isn't just a gimmick. For visual web scraping, automated interface testing, and RPA automation, this feature is a game-changer. I've automated entire workflows on interfaces that other models couldn't even read correctly.
Multi-agent systems
If you're building AI agent teams, Claude is natively optimized for that. Orchestration is smooth, context management is automatic, and I measured a 15% improvement on my deep research workflows.
Enterprise tasks
Professional document generation, Excel automation (+20% performance in my tests), complex financial reports: Claude Opus 4.5 handles it all like a pro.

GPT-5.2: where it shines
To be honest, GPT-5.2 also has serious arguments. And on some points, it's clearly ahead.
The mathematical brain
100% on AIME 2025 without external tools. That's just insane. If you're working on advanced logic problems, optimization, or abstract reasoning, GPT-5.2 is clearly superior. On ARC-AGI-2, it scores 52.9% versus 37.6% for Claude - that's not a trivial gap.
XXL context
400K tokens changes everything for certain use cases. You can load entire technical documentation, massive codebases, or hundreds of PDFs in a single request. For deep research on large corpora, it's unbeatable.
Multimodal versatility
GPT-5.2's advanced video analysis is really a step above. If your workflow involves processing lots of varied visual content (complex diagrams, videos, images), it will perform better.
The ChatGPT ecosystem
Let's be real: the ChatGPT ecosystem is more mature. Plugins, interface, community... If you want an "all-in-one" model for varied tasks, GPT-5.2 remains a solid choice.
Pros and cons
+ Claude Opus 4.5
- Absolute leader in code and debugging (80.9% SWE-bench)
- Unique screen zoom for UI automation
- Native and optimized multi-agent
- 67% cheaper than Opus 4.1
- Better first-attempt success rate
- Claude Opus 4.5
- More limited context window (200K vs 400K)
- Mathematical reasoning lags behind
- Basic video analysis
+ GPT-5.2
- Exceptional mathematical reasoning (100% AIME)
- Massive 400K token window
- Advanced video analysis
- Mature and versatile ecosystem
- GPT-5.2
- GPT-5.2 Pro is very expensive
- No screen zoom for UI automation
- Less effective on real-world code
My advice
If you have to choose just ONE model, ask yourself this question: "Do I do more coding or more math?" For daily software development, Claude Opus 4.5 is my choice without hesitation. For research, large document analysis, or complex reasoning problems, GPT-5.2 takes the lead. And honestly? The best strategy in 2025 is to have access to both and switch based on the task.
My verdict: which one to choose based on your needs
After weeks of testing, here's my decision guide:
Choose Claude Opus 4.5 if you:
- Do daily software development and debugging
- Build AI agents or multi-agent systems
- Need interface automation (RPA, UI testing)
- Work on critical enterprise workflows
- Want to optimize your budget on high volume
Choose GPT-5.2 if you:
- Work on mathematical or advanced logic problems
- Need to analyze massive document corpora (400K tokens)
- Need generalist multimodal analysis (especially video)
- Prefer a mature and versatile ecosystem
- Do scientific or academic research
My personal choice? For my daily workflow (code, automation, content creation), Claude Opus 4.5 has become my go-to. But I keep GPT-5.2 Pro handy for complex reasoning problems.
Frequently asked questions
Is Claude Opus 4.5 really better than GPT-5.2 for coding?
Yes, on real-world code benchmarks (SWE-bench Verified), Claude scores 80.9% compared to 80% for GPT-5.2. The difference is most noticeable on complex debugging tasks where Claude succeeds more often on the first try.
Which one is cheaper to use?
GPT-5.2 Instant is cheaper per token ($1.75 vs $5 for input), but Claude Opus 4.5 is often more cost-effective in practice due to its superior efficiency that reduces the number of iterations needed.
Can I use both models together?
Absolutely, and that's actually what I recommend for complex projects. Claude for code and automation, GPT-5.2 for mathematical reasoning and large document analysis.
Which model is more secure?
Both have made enormous progress. Claude Opus 4.5 relies on Constitutional AI philosophy and maximum robustness against prompt injections. GPT-5.2 has reduced its hallucination rate. For critical applications, both require human validation.
Conclusion
In December 2025, the Claude Opus 4.5 vs GPT-5.2 match has no absolute winner. Each model excels in its domain: Claude dominates code and automation, GPT-5.2 shines in reasoning and massive context. The real game changer is understanding your specific needs and choosing the right tool. And honestly? Having access to both in 2025 is a luxury we couldn't have even imagined 3 years ago.
About the author: Flavien Hue has been testing and analyzing artificial intelligence tools since 2023. His mission: democratizing AI by providing practical and honest guides, without unnecessary technical jargon.